6.3 二叉树基本操作的实现
二叉树的基本操作在 6.2.1 小节中已经定义,在这些操作中有一组非常重要的操作就是遍历操作,下面首先介绍遍历及其实现,然后介绍其他操作的实现。
在以下操作的实现中涉及了实现二叉树的 BinaryTreeLinked 类中定义的两个成员变量:一个是二叉树结点类型的root 变量,它指向二叉树的根结点;另一个是第三章中定义的 Strategy 接口类型变量 strategy,用于完成数据元素之间的比较操作。
所谓树的遍历( traversal),就是按照某种次序访问树中的所有结点,且每个结点恰好访问一次。也就是说,按照被访问的次序,可以得到由树中所有结点排成的一个序列。树的遍历也可以看成是人为的将非线性结构线性化。这里的“访问”是广义的,可以是对结点作各种处理,例如输出结点信息、更新结点信息等。在我们的实现中,并不真正的“访问”这
些结点,而是得到一个结点的线性序列,以线性表的形式输出。
回顾二叉树的定义,我们知道二叉树可以看成是由三个部分组成的:一个根结点、根的左子树和根的右子树。因此如果能够遍历这三部分,则可以遍历整棵二叉树。如果用 L、 D、R 分别表示遍历左子树、访问根结点、遍历右子树。那么对二叉树的遍历次序就可以有 6 种方案:
⑴ 遍历左子树,访问根,遍历右子树( LDR)
⑵ 遍历左子树,遍历右子树,访问根( LRD)
⑶ 访问根,遍历左子树,遍历右子树( DLR)
⑷ 访问根,遍历右子树,遍历左子树( DRL)
⑸ 遍历右子树,遍历左子树,访问根( RLD)
⑹ 遍历右子树,访问根,遍历左子树( RDL)
在上述 6 种遍历方案中,如果规定对左子树的遍历先于对右子树的遍历,那么还剩下 3种情况: DLR、 LDR、 LRD。根据对根访问的不同顺序,分别称 DLR 为先根(序)遍历,LDR 为中根(序)遍历, LRD 为后根(序)遍历。
请注意,这里的先序遍历、中序遍历、后序遍历是递归定义的,即在左右子树中也是按相应的规律进行遍历。下面给出三种遍历方法的递归定义。
⑴ 先序遍历( DLR)二叉树的操作定义为:
若二叉树为空,则空操作;否则
① 访问根结点;
② 先序遍历左子树;
③ 先序遍历右子树。
⑵ 中序遍历( LDR)二叉树的操作定义为:
若二叉树为空,则空操作;否则
① 中序遍历左子树;
② 访问根结点;
③ 中序遍历右子树。
⑶ 后序遍历( LRD)二叉树的操作定义为:
若二叉树为空,则空操作;否则
① 后序遍历左子树;
② 后序遍历右子树;
③ 访问根结点。
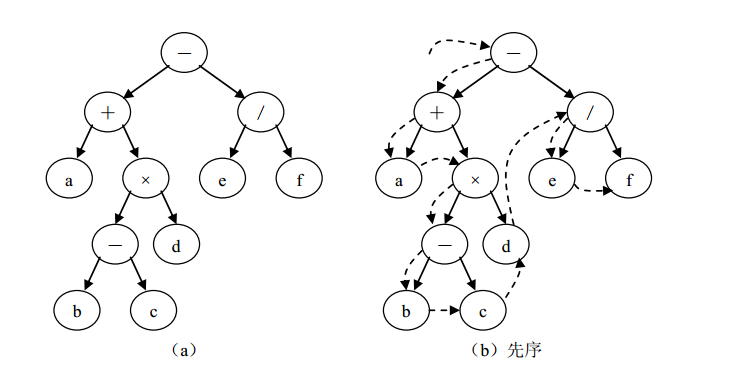
下面先以一棵二叉树表示一个算术表达式,然后对其进行遍历。以二叉树表示表达式的递归定义如下:若表达式为数或简单变量,则相应二叉树中仅有一个根结点;若表达式=(第一操作数)(运算符)(第二操作数),则相应二叉树用左子树表示第一操作数,用右子树表示第二操作数,根结点存放运算符。
例如图 6-6( a)所示的二叉树表示下述表达式a+ (b- c)×d- e/ f
如果对该二叉树进行三种遍历,分别得到的遍历序列如下
先序遍历( DLR):- + a × - b c d / e f
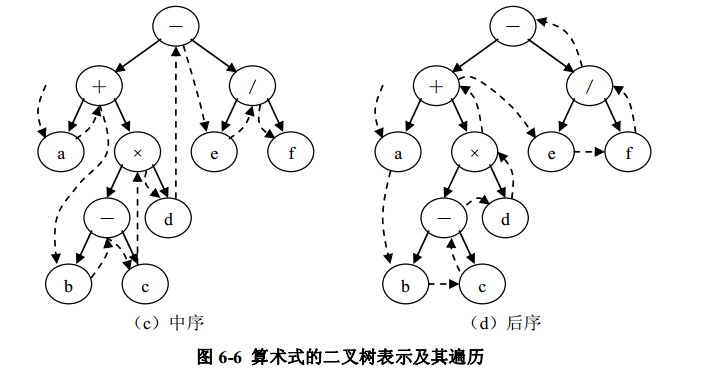
中序遍历( LDR): a + b - c × d - e / f
后序遍历( LRD): a b c - d × + e f / -
从表达式上看,以上三个序列正好是表达式的前缀表示(波兰式)、中缀表示和后缀表示(逆波兰式)。在计算机中,使用后缀表达式易于求值。
上述遍历的过程显然是一个递归的过程,因此可以很容易的写出三种遍历的递归程序,下面仅给出先序遍历二叉树基本操作的递归算法在三叉链表上的实现。中序遍历和后序遍历的递归算法与先序遍历的递归算法类似,这里不再一一列举。
算法 6-1 preOrder
输入: 无
输出: 迭代器对象,先序遍历二叉树结果
代码:
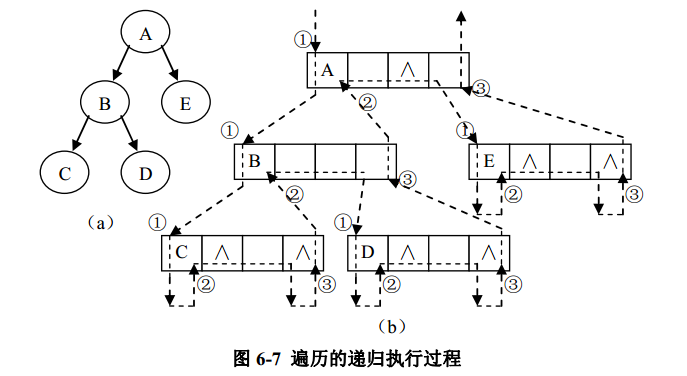
//先序遍历二叉树 public Iterator preOrder() { LinkedList list = new LinkedListDLNode(); preOrderRecursion(this.root,list); return list.elements(); } //先序遍历的递归算法 private void preOrderRecursion(BinTreeNode rt, LinkedList list){ if (rt==null) return; //递归基,空树直接返回 list.insertLast(rt); //访问根结点 preOrderRecursion(rt.getLChild(),list); //遍历左子树 preOrderRecursion(rt.getRChild(),list); //遍历右子树 } 算法中是将结点加入链接表 list 的尾部作为对结点的访问,该操作只需要常数时间即可完成(在随后的算法中也有同样的结论)。在算法的递归执行过程中,每个结点访问且仅被访问一次,因此算法的时间复杂度 T(n) = Ο (n)。对于中序和后序遍历的递归算法也是如此,即中序和后序递归算法的时间复杂度也是Ο (n)。二叉树的先序、中序和后序遍历操作,其不同之处仅在于访问访问根、左子树、右子树的顺序不同而已,实则三种遍历方法的递归执行过程是一样的。图 6-7( b)中用带箭头的虚线表示了三种遍历算法的递归过程。其中,向下的箭头表示更深一层的递归调用,向上的箭头表示从递归调用推出返回。在图 6-7( b)中可以看到每个结点在遍历过程中都被途经 3次,三种不同的遍历只是在该执行过程中的不同时机返回根结点而已。先序遍历是在第一次向下进入根结点时访问根结点,中序遍历是第二次从左子树递归调用返回时访问根,后序遍历是第三次从右子树递归调用返回时访问根。虚线旁边的①、②、③就是三种不同的访问根结点的时机,分别对应先序、中序和后序遍历
根据上述先序、中序和后序遍历递归算法的执行过程,可以写出相应的先序、中序和后序遍历的非递归算法。
算法 6-2 preOrder
输入: 无
输出: 迭代器对象,先序遍历二叉树的结果
代码:
public Iterator preOrder() { LinkedList list = new LinkedListDLNode(); preOrderTraverse (this.root,list); return list.elements(); } //先序遍历的非递归算法 private void preOrderTraverse(BinTreeNode rt, LinkedList list){ if (rt==null) return; BinTreeNode p = rt; Stack s = new StackSLinked(); while (p!=null){ while (p!=null){ //向左走到尽头 list.insertLast(p); //访问根 if (p.hasRChild()) s.push(p.getRChild()); //右子树根结点入栈 p = p.getLChild(); } if (!s.isEmpty()) p = (BinTreeNode)s.pop(); //右子树根退栈遍历右子树 } } 算法 6-2 说明: preOrderTraverse 方法以一棵树的根结点 rt 以及链接表 list 作为参数。如果 rt 为空直接返回,否则 p 指向 rt,并先序遍历以 p 为根的树。在 preOrderTraverse 内层循环中,沿着根结点 p 一直向左走,沿途访问经过的根结点,并将这些根结点的非空右子树入栈,直到 p 为空。此时应当取出沿途最后碰到的非空右子树的根,即栈顶结点(以 p 指向),然后在外层循环中继续先序遍历这棵以 p 指向的子树。如果堆栈为空,则表示再没有的右子树需要遍历,此时结束外层循环,完成整棵树的先序遍历。如果以 rt 为根的树的结点数为 n,由于每个结点访问且仅被访问一次,并且每个结点最多入栈一次和出栈一次,因此preOrderTraverse 的时间复杂度 T(n) = Ο (n)。
算法 6-3 inOrder
输入: 无
输出: 迭代器对象,中序遍历二叉树的结果
//中序遍历二叉树 public Iterator inOrder(){ LinkedList list = new LinkedListDLNode(); inOrderTraverse (this.root,list); return list.elements(); } //中序遍历的非递归算法 private void inOrderTraverse(BinTreeNode rt, LinkedList list){ if (rt==null) return; BinTreeNode p = rt; Stack s = new StackSLinked(); while (p!=null||!s.isEmpty()){ while (p!=null){ //一直向左走 s.push(p); //将根结点入栈 p = p.getLChild(); } if (!s.isEmpty()){ p = (BinTreeNode)s.pop();//取出栈顶根结点访问之 list.insertLast(p); p = p.getRChild(); //转向根的右子树进行遍历 }//if }//out while } 算法 6-3 说明: inOrderTraverse 方法以一棵树的根结点 rt 以及链接表 list 作为参数。如果 rt 为空直接返回,否则 p 指向 rt,并中序遍历以 p 为根的树。在 inOrderTraverse 内层循环中,沿着根结点 p 一直向左走,沿途将根结点入栈,直到 p 为空。此时应当取出上一层根结点访问之,然后转向该根结点的右子树进行中序遍历。如果堆栈和 p 都为空,则说明没有更多的子树需要遍历,此时结束外层循环,完成整棵树的遍历。 inOrderTraverse 的时间复杂preOrderTraverse 一样 T(n) = Ο (n)。
算法 6-4 postOrder
输入: 无
输出: 迭代器对象,后序遍历二叉树的结果
代码:
//后序遍历二叉树public Iterator postOrder(){LinkedList list = new LinkedListDLNode();postOrderTraverse (this.root,list);return list.elements();}//后序遍历的非递归算法private void postOrderTraverse(BinTreeNode rt, LinkedList list){if (rt==null) return;BinTreeNode p = rt;Stack s = new StackSLinked();while(p!=null||!s.isEmpty()){while (p!=null){ //先左后右不断深入s.push(p); //将根节点入栈if (p.hasLChild()) p = p.getLChild();else p = p.getRChild();}if (!s.isEmpty()){p = (BinTreeNode)s.pop(); //取出栈顶根结点访问之list.insertLast(p);}//满足条件时,说明栈顶根节点右子树已访问,应出栈访问之while (!s.isEmpty()&&((BinTreeNode)s.peek()).getRChild()==p){p = (BinTreeNode)s.pop();list.insertLast(p);}//转向栈顶根结点的右子树继续后序遍历if (!s.isEmpty()) p = ((BinTreeNode)s.peek()).getRChild();else p = null;}} 算法 6-4 说明: postOrderTraverse 方法以一棵树的根结点 rt 以及链接表 list 作为参数。如果 rt 为空直接返回,否则 p 指向 rt,并后序遍历以 p 为根的树。在 postOrderTraverse 内层第一个 while 循环中,沿着根结点 p 先向左子树深入,如果左子树为空,则向右子树深入,沿途将根结点入栈,直到 p 为空。第一个 if 语句说明应当取出栈顶根结点访问,此时栈顶结点为叶子或无右子树的单分支结点。访问 p 之后,说明以 p 为根的子树访问完毕,判断 p是否为其父结点的右孩子(当前栈顶即为其父结点),如果是,则说明只要访问其父亲就可以完成对以 p 的父亲为根的子树的遍历,以内层第二个 while 循环完成;如果不是,则转向其父结点的右子树继续后序遍历。如果堆栈和 p 都为空,则说明没有更多的子树需要遍历,此时结束外层循环,完成整棵树的遍历。 postOrderTraverse 的时间复杂度分析和先序、中序遍历算法一样,其时间复杂度 T(n) = Ο (n)。对二叉树进行遍历的搜索路径,除了上述按先序、中序和后序外,还可以从上到下、从
左到右按层进行。层次遍历可以通过一个队列来实现,算法 6-5 实现了这一操作。
算法 6-5 levelOrder
输入: 无
输出: 层次遍历二叉树,结果由迭代器对象输出。
代码:
//按层遍历二叉树public Iterator levelOrder(){LinkedList list = new LinkedListDLNode();levelOrderTraverse(this.root,list);return list.elements();}//使用队列完成二叉树的按层遍历private void levelOrderTraverse(BinTreeNode rt, LinkedList list){if (rt==null) return;Queue q = new QueueArray();q.enqueue(rt); //根结点入队while (!q.isEmpty()){BinTreeNode p = (BinTreeNode)q.dequeue(); //取出队首结点 p 并访问list.insertLast(p);if (p.hasLChild()) q.enqueue(p.getLChild());//将 p 的非空左右孩子依次入队if (p.hasRChild()) q.enqueue(p.getRChild());}} 在算法 6-5 中,每个节点依次入队一次、出队一次并访问一次,因此算法的时间复杂度T(n) = Ο (n), n 为以 rt 为根的树的结点数。下面来分析二叉树其他基本操作的实现。由于在 BinTreeNode 中结点的高度、规模等信息已经保存,并且在发生变化时都进行了更新,因此 getSzie ()、 getHeight()操作在常数时间内就能完成。 isEmpty ()、 getRoot()在根结点引用的基础上进行简单的比较和返回即可。树中结点的添加和删除通过结点自身的方法可以完成。唯一稍微复杂的操作是 find(e)方法的实现。算法 6-6 实现了这个操作。
算法 6-6 find
输入: 元素 e
输出: e 所在结点
代码:
//在树中查找元素 e,返回其所在结点public BinTreeNode find(Object e) {return searchE(root,e);}//递归查找元素 eprivate BinTreeNode searchE(BinTreeNode rt, Object e) {if (rt==null) return null;if (strategy.equal(rt.getData(),e)) return rt; //如果是根结点,返回根BinTreeNode v = searchE(rt.getLChild(),e); //否则在左子树中找if (v==null) v = searchE(rt.getRChild(),e); //没找到,在右子树中找return v;} 算法 6-6 按先序顺序在二叉树中查找元素 e,并返回找到的第一个结点,如果没有找到则返回 null。算法中最多进行 n 次结点元素的比较,因此算法的时间复杂度 T(n) = Ο (n)。其中 strategy 为实现的二叉树的成员变量。